Møte 8 i FHIR fagforum
- Dato: 2021-10-20
- Klokkeslett: 1300-1500
- 42 deltakere
FHIR fagforum (FFF) er et åpent forum om bruk og implementering av HL7 FHIR i Norge. FFF er åpent for alle.
Agenda
- Velkommen og presentasjonsrunde (alle skriver i chatten hvor de kommer fra + aktuell erfaring/prosjekt), Thomas T Rosenlund, Direktoratet for e-helse (5 min)
- Informasjon fra HL7 Norge Øyvind Aassve, Sykehuspartner (5 min)
- Intro til dokumentasjon/profileringspipeline, Thomas Tveit Rosenlund, Direktoratet for e-Helse (20 min)
- Build pipeline med FSH, Eirik Myklebost, NAV (40 min)
- Spark rammeverket muligheter og demo, implementerer et API endepunkt, Kenneth Myhra, NHN (40 min)
- Eventuelt
Presentasjoner
- Agenda, intro og intro til profilering FHIR fagforum nr 8 og intro til profilering og build
- Build pipeline med FSH FHIR IG dev. + CI/CD
- Spark rammeverk demo Spark FHIR facade
{kind=link}
HL7 Norge - Øyvind AAssve
- Procedure godkjent i TSK 15. oktober
- Virtuelt WGM gjennomført, Implementation division opprettes i HL7 international med hovedfokus på implementering og IG
- Profilerings rammeverk i Norge
- Pågående aktiviteter på basisprofilering - Tarmscreening procedure er godkjent
- HSØ - Appointment, Encounter, Slot, EOC osv.
- Observation - vital-signs er i profilering
- CarePlan og DiagnosticReport - behov for arbeid
Thomas Tveit Rosenlund - Profilering, dokumentasjon og Implementasjonsguide
Profilering og build pipeline på fire måter.
Eirik Myklebost - Build pipeline med FSH
Arbeidet med FHIR et par år Implementation Guide IG - vanligvis en HTML side Eksempler på IG CI/CD pipeline - automatisering av stegene FSH kode - Shorthand - kompileres til Conformance ressurser, passer godt sammen med en Git kildekodekontroll
- Kan hooke på events i repo, GitHub actions spinner opp en container som kjører workflowen (scriptet) som er definert
- Build-pipeline til NAV inneholder et steg for testing, teste at eksempelressurser gir forventet valideringsutfall
- Autogenererte testrapporter mot forhåndsdefinerte eksempler
- IG-publisher for å generere html -
- committes til github pages branchen
- Ny versjon fører til ny pakke publiseres - NPM pakke fra IG-publisher
- Lage release til FHIR package registry
- Pakke releases på SIMPLIFIER blir automatisk tilgjengelig i FHIR Package registry
- Releases - run template og committes til gh-pages, registrer denne
HL7 international har bygget en auto-ig builder - den bygger for deg og publiserer, men man mister litt kontroll. Containeren fra HL7
IG-publisher kan lages som GitHub action
Spørsmål
to IG-er i repoet - versjonering uavhengig av hverandre noen vil være mer utvikling og noen er mer stabile
Det finnes et offisielt Docker image for build som man kan benytte i GitHub actions for autobygg av IG
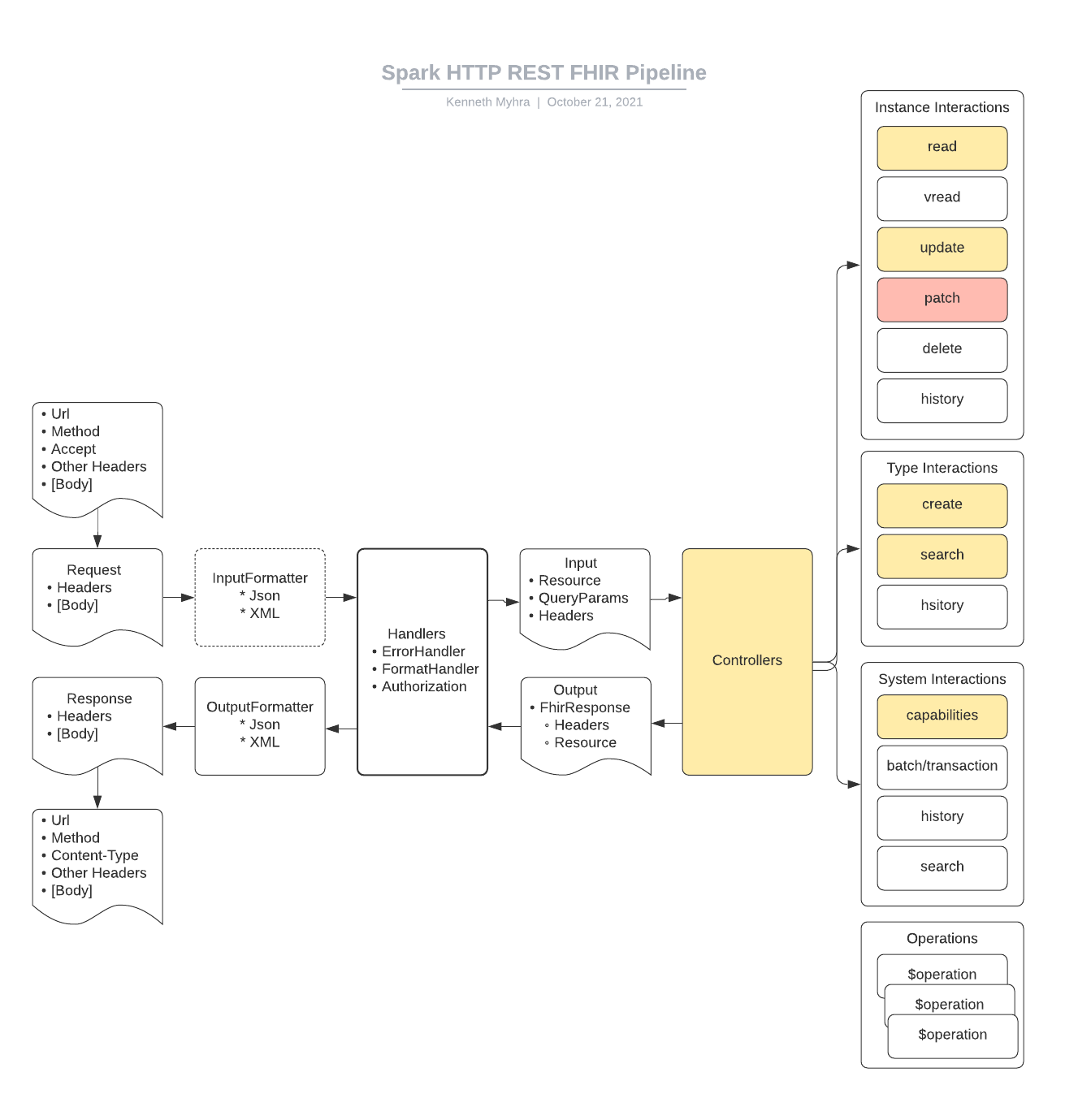
Kenneth Myhra - Spark rammeverk og FHIR server
Fasade vs FHIR server
- Sette opp FHIR API på eksisterende tjenester
- Trenger kontroll over egen informasjons/datamodell
Sette opp en fasade
- Sette opp interaksjoner
- Request - Handles - Kontroller og legges til definisjon av interaksjoner
- ASP .NET core prosjekt
- Sette opp pipeline med settings
- Sette opp, GET, søk, PUT og POST for FHIR ressurser på serveren ved hjelp av Spark rammeverket
Fasade
- må definere alle interaksjonene selv i egen kode, hvis man har generell FHIR server er standardinteraksjoner definert av server. Det må også defineres hvordan informasjonen skal lagres/hentes i databasen.
- CapabilityStatement skiller ikke på POST eller GET for søk
- Må hente informasjon fra innkommende/utgående ressurser og skrive kode for hvordan disse ressursene håndteres mot database
Spørsmål Spark
- Proprietære API men får bare bruke FHIR internt i sykehuspartner, bare READ, hvor mye ressursinnsats for å implementere en Fasade i praksis.
- Ønsker at det skal benyttes FHIR API for informasjonen som kommer ut, hva er utfordringene?
- Tilgang til databasen, kan det brukes hvis det er lov, ellers må man kalle API’ene og må gjøre mapping i mellom
- Benytte rammeverket og benytte første del av produktet, men resten (logikken) må skrives for tjenesten
- Formatering og feilhåndtering får man da ut av fasaden
- Hvis man skal kjøre Include på andre ressurser, blir det mye mer kompleks kode?
- Den biten med include må du skrive selv
- Opphenting og tolking over til din database må du du skreddersy selv i egen kode
- Endel mer kompleks kode
- Profil - la oss si du har Observations som mapper til forskjellige profiler, kan man angi forskjellige operasjoner mot profilen
- Pipelinen din må håndtere hvordan mappingen skal gjøres basert på forskjellige profiler
- Men du må skrive koden selv i en fasade
- Du kan få profilene som parametere i kallet og håndtere det der
There is a high cost concerned supporting include/revinclude in a facade implementation
- Chaining could be implemented but it is hard to do